2020년 9월에 세계적인 학술지 Nature 본지에서 NumPy에 대한 리뷰 논문이 나왔습니다.
사실 NumPy가 워낙 직관적이라, 특별한 목적이 아니라면 깊이 생각해보고 사용하지는 않는 libaray입니다.
Python 내장 기능도 아닌 특별한 Library인 NumPy는 숫자 처리에 없어선 안될 Libaray입니다.
Python에 대한 기본적인 내용은 포스팅 까먹기 쉬운 python 함수을 참조하시길 바랍니다.
본 포스팅은 Nature지의 "Array programming with NumPy" doi.org/10.1038/s41586-020-2649-2 를 요약하였으며, 더 깊은 내용은 실제 논문을 참조하시길 바랍니다.
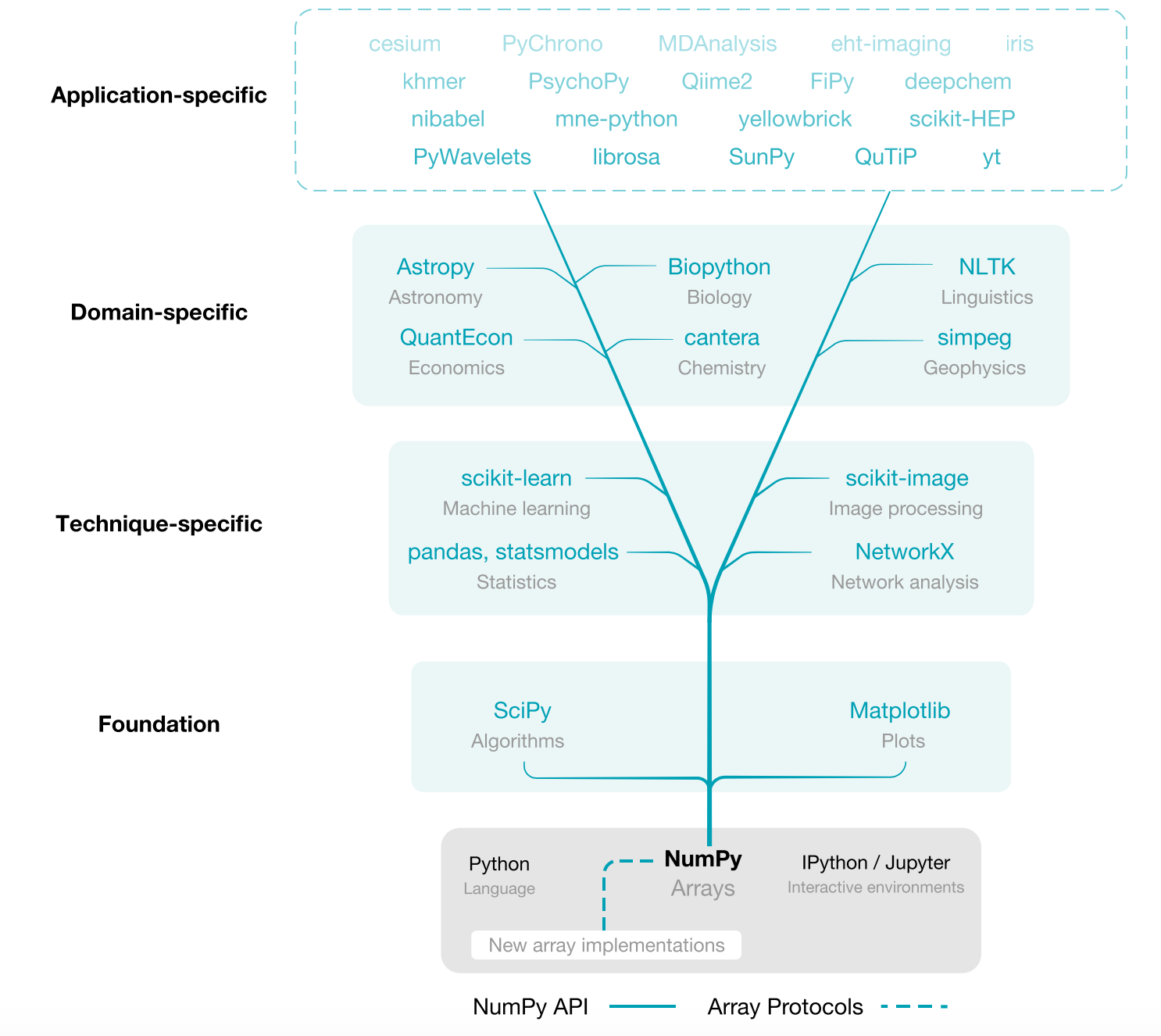
NumPy는 데이터를 array로 다루는 방법으로, MATLAB을 사용하신 분이라면 거부감 없이 사용할 수 있는 Libaray입니다. NumPy가 중요한 이유는 과학적 데이터 계산에 사용하는 SciPy, Matplotlib, pandas, scikit-learn, scikit-image에 기본이 되는 libaray이기 때문입니다.
사용되는 API와 메커니즘은 array에 특화되었고, 연산은 CPU를 사용합니다.

다음 그림과 같이 data, data type, shape, strides라는 변수로 array를 구성합니다. 각 data 요소들은 같은 메모리를 차지합니다. strides는 shape이 결정되면, 당연히 결정되는 요소라 생각할 수 있지만, computor memory측면에서 1D로 저장할 수 있게 해주는 요소입니다. array를 다루는 다양한 방법이 있는데 대표적으로, indexing(view, copy), Vectorization, Broadcasting, Reduction이 있습니다.
기능으로 대부분의 수학연산이 제공되며, 보통 np.으로 API가 구성됩니다.
최근에 Deep learning에 사용되자 CPU를 넘어 연산할 수 있게 발전되었습니다.
PyTorch, Tensorflow, Apache MXNet, JAX와 같은 곳에서, GPU를 같이 이용할 수 있게 구성하였습니다.
상위 Libaray에서도 NumPy의 연산속도를 높여주었는데, SciPy와 PyData/Sparse도 메모리를 효율적으로 이용할 수 있게 연산하게 도와줍니다.
이처럼 NumPy 자체 발전에 더하여, 상위 Libaray에서 NumPy 연산효율을 극대화 시킵니다.
다시말해 np.은 자체의 데이터 사이언스 대부분 libaray에서 이용이 됩니다. 비록 컴퓨터 구조가 변화하며, Rust, Julia, LLVM과 같은 새로운 언어가 등장하고 있지만, 데이터 처리의 기본적인 libaray로 이러한 흐름에 발맞춰 변화하고 있습니다.
'Review' 카테고리의 다른 글
| 저전력 반도체 기술 (Power reduction) (0) | 2021.04.18 |
|---|---|
| 강유전체 + 강자성체 : ferroelectric spintronics (0) | 2020.10.02 |
| 왜 Spintronics 인가 (5) | 2020.08.19 |
| SOT-MRAM (0) | 2020.08.01 |
| 뉴로모픽 컴퓨팅 (Neuromorphic Computing) _ 인공지능 (1) | 2020.07.27 |

